
pandas概述
import pandas as pd与基本的numpy相比,pandas库是用来处理 表格型 数据 或者 异构型 数据的。相对的,最基本的numpy更适合处理 相同类型的数值类数组数据。
pandas库中内置了两个数据结构:Series和DataFrame。
缺失值
pandas的设计目标之一就是 尽可能简单的处理缺失数据。这将大幅简化我们的数据清洗操作。
NaN, 即Not a number,是一个浮点值。 pandas处理空缺值的方式就是把一个数据赋值为NaN。NaN值被pandas的诸如mean()之类的函数自动的跳过。不同函数处理NaN的行为不同,有的直接报错,有的忽略它。
python内建的None、numpy中的nan都在使用pandas的时候都被自动处理为NaN。
索引的概念
索引是map的键,就这么简单。但是,在pandas数据结构中,它允许重复。
索引对象
index属性可以获取pandas对象的索引。这个引用的索引通过[]和.取的值不允许被直接修改,是只读属性。索引对象类似于集合(但里面的元素是可重复的),它内置了一些集合运算的方法帮助我们筛选索引。
Series
series是一个一维数组对象,只不过它的每一个下标对应一个索引(index)。所以,一个长度固定并且有序的map,就是series。
class pandas.Series(data=None, index=None, dtype=None, name=None)data参数可以是一个列表,也可以是一个字典。如果是一个字典,它的index将被自动赋值为键。如果显式的传入index,则它的优先级最高。不在index列表中的缺失值将自动填充NaN。
sdata = {'a': 1, 'b': 2, 'c': 3};
s = pd.Series(sdata, index = ['b', 'a', 'd'])
s
"""
output:
b 2.0
a 1.0
d NaN
dtype: float64
"""dtype参数和numpy的数组一样,表示数据的类型。
name参数,则是Series对象的另一个基本属性。Series对象和它的索引都有name属性。
DataFrame
可以被视为二维的Series,也就是二维有序的map。说白了,就是一张excel表格。
可以视为一个共享相同索引的Series的有序字典。
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)data传入的最常见方式是一个包含了等长度列表作为值的字典。字典的每一个键值对就是一个Series列。
另一种传入方式是嵌套字典。这种情况下外层键值对的键将作为列索引,内层键值对的键作为行索引。
index是行索引,colunms参数是列索引。
dtype默认为None。如果强制DataFrame必须只有一种数据类型,可以指定它。
copy表示是否从data拷贝数据。对于data传入的是一个DataFrame的情况,copy默认是False,也就是引用了源数据。
数据处理
由于基于numpy,所以pandas数据结构很多行为上和numpy原生数组雷同。
选取数据
选取数据默认全部返回引用。
- df[clm]/df.clm
frame[column]和frame.column都可以用于选取列,但是前者对于任意列名有效,后者只对于python变量名有效。但是后者的这一特性决定了它可以享受Tab键的自动补全。前者的另一特性是它可以用于创建新列。
fr = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list('abc'), index=list('xyz'))
fr['a']
"""
x 0
y 3
z 6
Name: a, dtype: int32
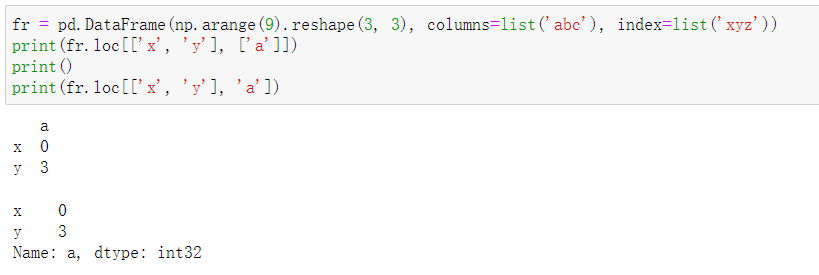
"""- df.loc[row, clm]
轴索引函数(location),row切出行,clm切出列。
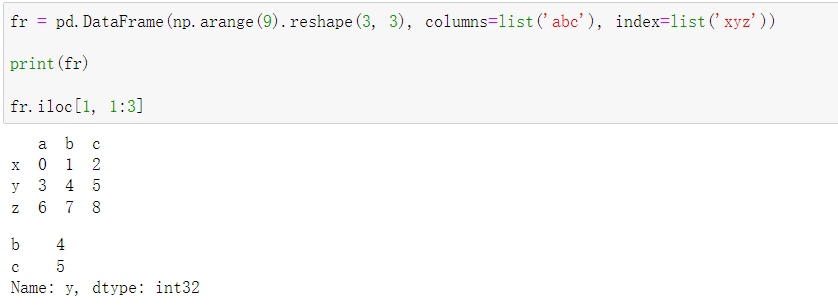
- df.iloc[row, clm]
整数索引函数(int location),row切出行,clm选中列。
- df.values属性
返回数据集中所有的数据组成的一个数组。
修改数据
算术
选取的数据全部都是引用,支持修改。
- 和标量进行运算
和numpy一样,pandas数据结构与标量之间的运算将传给数组中的每一个元素。
- Series自身和DataFrame自身的运算
和numpy一样。除了满足numpy的四则运算,还内置了一些运算函数,每组中的函数互为反函数。
| 方法 | 描述 |
|---|---|
| add, radd | 加法 |
| sub, rsub | 减法 |
| mul, rmul | 乘法 |
| div, rdiv | 除法 |
| floordiv, rfloordiv | 整除 |
| pow, rpow | 幂次方 |
DataFrame和Series之间的运算
和
numpy一样,pandas数据结构之间的运算依然满足广播机制。可以把
Series赋值给DataFrame的某一列。Series的索引会去匹配DataFrame的索引。如果不存在则补入NaN。
通用值替换
可以通过方括号或者.运算选中一个元素后进行单个值替换;如果要对某一个值全部替换,则可以用replace()。
索引的修改
reindex()用于重建索引。返回新的对象。
DataFrame.reindex(labels=None, *, index=None, columns=None, axis=None, method=None, copy=None, level=None, fill_value=nan, limit=None, tolerance=None)rename()用于修改索引。默认返回一个新的对象:
DataFrame.rename(mapper=None, *, index=None, columns=None, axis=None, copy=None, inplace=False, level=None, errors='ignore').index.map()也可以用于修改索引。map参见映射drop用于删除索引。
常见配套函数
通用函数
所有numpy中的通用函数都可以作用于pandas中,被称为通用函数。
映射函数
作用于每个元素上
对于Series,有一个map()函数,接收一个f,作用于每一个元素上;对于DataFrame,类似的函数名叫做applymap。
另外,index对象也含有一个map()函数,用于修改索引:
# index的修改
fr.index = fr.index.map(myf)作用于某一行/列
DataFrame的一个常见操作是,对某一行或者某一列进行处理。
apply()函数接收一个函数f,该函数默认传入DataFrame的每一列,然后把结果返回,最后得到的是一个以原DataFrame的列名作为索引的Series。
fr = pd.DataFrame(np.random.randn(3, 3), columns=list('abc'), index=list('xyz'))
f = lambda x : x.max() - x.min()
fr.apply(f)
"""
a 0.411482
b 1.914997
c 1.847477
dtype: float64
"""传入的f,不一定返回一个标量,也可以返回一个Series,这样得到的结果就变成了一个DataFrame:
fr = pd.DataFrame(np.random.randn(3, 3), columns=list('abc'), index=list('xyz'))
print(fr)
def f(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
fr.apply(f)
排序函数
sort_index()函数用于根据索引字典序排序,sort_values()根据值进行排序。sort_values()如下:
sort_values(by='##',axis=0,ascending=True, inplace=False, na_position='last')| 参数 | 说明 |
|---|---|
| by | 指定列名(axis=0或’index’)或索引值(axis=1或’columns’) |
| axis | 若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0 |
| ascending | 是否按指定列的数组升序排列,默认为True,即升序排列 |
| inplace | 是否用排序后的数据集替换原来的数据,默认为False,即不替换 |
| na_position | {‘first’,‘last’},设定缺失值的显示位置 |
排名函数
rank()用于根据每个值的相对大小对数据进行排名。相当于把每个数据改为了一个值,值越小排名越靠前。
默认情况下,如果两(多)个数据的值相等,则称为平级,这时rank()通过这两个值的排名平均值决定最后的值为多少(也就是相加除以2)。可以通过method参数改变这种默认行为。