
模块和依赖
分享会 PPT 演讲稿。
包和库、模块与依赖的管理,一直是 js 发展过程中老生常谈的话题。在这块的实现上,有社区版的,有官方的;有引擎方面实现的模块系统,也有在 js 基础上的函数封装实现。js 的复杂性,模块占一半。
(不)常见的模块实现
- YUI 雅虎
- CMD:seajs
- AMD:requireJS
- UMD
- ESM
大部分模块系统都已经没落了,主要讨论 ESM 和 CJS。
ES6 vs CJS
各自的步骤
- ES6 模块,在编译阶段就进行引用的获取,运行阶段进行加载。
- 在实现上,所有
import命令会被引擎提到前面,先于模块内的所有其他语句运行。 import()函数,和import命令的区别在于它不会被提到前面。它被执行后返回一个Promise,结果为是否加载完毕。由于这种按需加载的特性,它在前端代码的打包中常常会被作为分割点。
- 在实现上,所有
- CJS 被实现为一个 js 函数接口,在运行
require()时进行接口的获取,且获取的接口是简单的'='赋值(这对于值来说是拷贝,对于对象来说则是获取了引用。)
循环加载
一个有意思的行为是自己引用自己。
CommonJS 模块遇到循环加载时,返回的是当前已经执行的部分的值;
ES6 中由于引用接口是在编译阶段就持有的,所以需要开发者自己保证得到的引用的接口合法性:
// a.mjs
import { bar } from './b';
console.log('a.mjs');
console.log(bar);
export let foo = 'foo';
// b.mjs
import { foo } from './a';
console.log('b.mjs');
console.log(foo);
export let bar = 'bar';运行如下:
$ node --experimental-modules a.mjs
b.mjs
ReferenceError: foo is not defined执行 a.mjs 时候,首先运行 b.mjs,因此去执行 b.mjs。接着,执行b.mjs 的时候,它又 import 了 a.mjs,引擎发现发生了循环引用,这时不会再跳过去运行 a.mjs,而是认为这个模块已经加载了,继续往下执行。执行到第三行console.log(foo)的时候,才发现这个对 foo 的引用根本还没定义(即文件中不存在名为 foo 的变量),因此报错。
ES6 的两个特点
后缀不可省略与查询参数
ES6 模块的加载路径必须给出脚本的完整路径,不能省略脚本的后缀名 .js 或者 mjs。
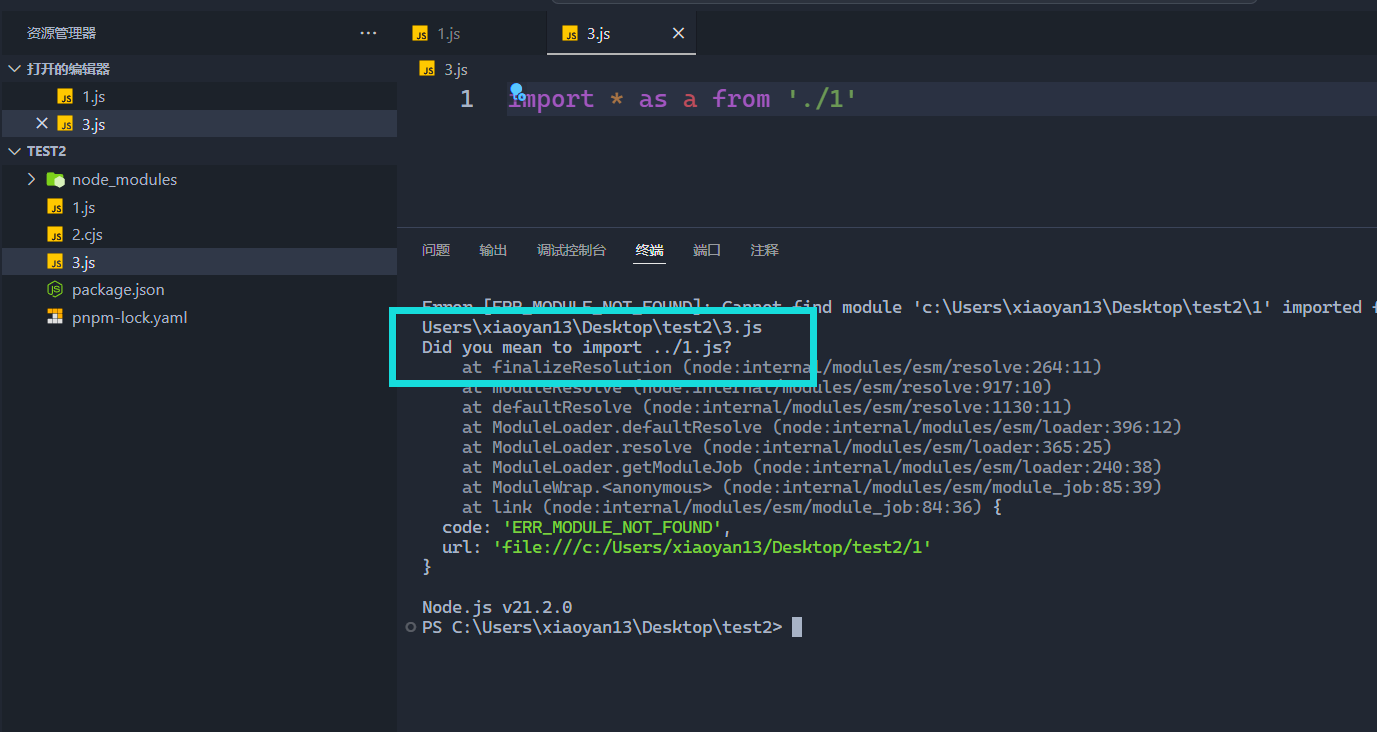
一个理念是,ES6 模块应该是通用的,同一个模块不用修改,就可以用在浏览器环境和服务器环境。为了与浏览器的 import 加载规则相同,Node.js 的 .mjs 文件支持 URL 路径:
import './foo.mjs?query=1'; // 加载 ./foo 传入参数 ?query=1上面代码中,脚本路径带有参数?query=1,Node 会按 URL 规则解读。同一个脚本只要参数不同,就会被加载多次,并且保存成不同的缓存, 从而持有不同文件的引用。这也是 vite 的核心原理之一: http query params 进行脏检查。
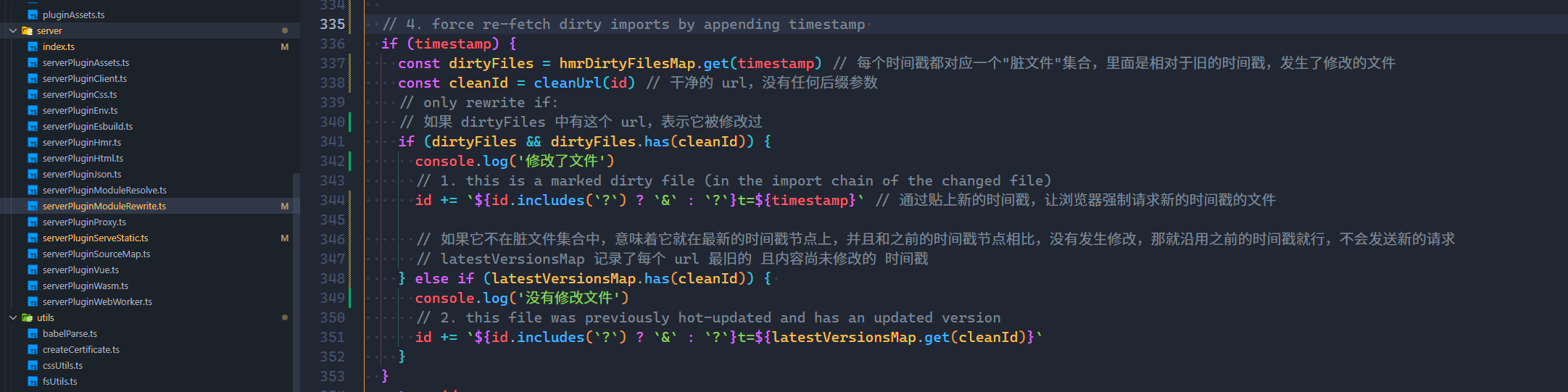
vite 使用 t 参数作为唯一的标识时间戳。第一次启动没有 t 参数, 在后台改动代码后,网络页面出现 t 参数:
最后,由于这个原因,只要文件名中含有:、``%、#、?等特殊字符,最好对这些字符进行转义,确保他们不会被 node` 识别为查询参数。
this
最后,就是 this 关键字。ES6 模块之中,顶层的 this 被实现为指向 undefined,而非报错。
Node 对 es6 的支持
ES6 模块在规范层面影改变了 js运行时 (即 node)的实现,原先的 node.js 的模块系统不支持 import/export,需要新的 ES6 模块系统来支持。新旧模块系统的具体实现互不兼容。
Node.js 要求 ES6 模块采用 .mjs 后缀文件名。也就是说,只要脚本文件里面使用 import 或者 export 命令,那么就必须采用 .mjs 后缀名。Node.js 遇到 .mjs 文件,就认为它是 ES6 模块,默认启用严格模式。
库与依赖
npm
对于一个项目而言,最终肯定是要拿来用的。至于怎么用,有两种方式:
被开发者使用,以库的形式。
被用户使用,用于跑生产环境。
npm 作为包管理工具,给我们提供了第一种方式的解决方案。所有的 js 项目/库,无论是打包后的还是没有打包的,都通过一个叫做 package.json 的文件联系起来,互相认识。
用于生产环境
我们先看第二种情况,因为这种情况最简单。
!灵魂拷问:我们上线的项目中,使用的 dependencies 和 devDependencies 有什么区别?
答案:没有任何区别。
如果项目用于第二种用途, dependencies 和 devDependencies 没有任何区别:各种依赖对于这个项目来说都只是单纯的依赖。如果只是一个用来跑的项目,将来不会变成别人项目的一部分,那么依赖安装在 dependencies 和 devDependencies 是没有任何区别的。
这也就是为什么我在迁移 vite 项目的时候,把所有的依赖,全部尽可能的安装在 dependencies 上的理由。
被开发者使用
复习一下,安装和使用一个库很简单:
npm install (with no args, in package dir)
npm install <tarball file> # 安装位于文件系统上的包。
npm install <tarball url> # 获取 url,然后安装它。为了区分此选项和其他选项,参数必须以“http://”或“https://”开头。
npm install <folder> # 安装位于文件系统上某文件夹中的包
npm install [<@scope>/]<name> # 安装指定的包的最新版本。
npm install [<@scope>/]<name>@<tag> # 安装被 tag 引用的包的版本。如果 tag 不存在于该包的注册表数据中,则失败。
npm install [<@scope>/]<name>@<version> # 安装指定的包的版本。如果版本尚未发布到注册表,则失败。
npm install [<@scope>/]<name>@<version range> # 安装与指定版本范围相匹配的包版本。但无论是使用库,还是一个安装库,都必须要考虑这个库的 定位。一个库的定位取决于自己的项目要拿这个库干什么。根据不同的定位,npm 在打包阶段当前项目时对依赖的处理和下载时对依赖的态度会变化。定位有几种:
bundledDependencies:最简单的情况,这些项目依赖,是我的项目在打包时就进行处理的,它们一开始在我的项目发布时,就被打进了我的包中,所以他会增大最终的js文件的体积。别人用的时候不需要安装。dependencies:这些项目依赖,发布后,别人正常使用我的库(项目)时需要它们。库在被下载的时候,package.json中的所有dependencies会自动安装。peerDependencies:这些项目依赖,是我的项目在打包时不进行处理的,它不会自动安装。这意味着,如果自己的环境中没有事先拥有想安装的库的package.json中的peerDependencies,或者版本不匹配,npm抛出警告,让你先安装。也可以通过optional选项来标识此依赖其实是可选的,不需要抛出警告。(在最新版本的npm和pnpm中,该选项被改为会自动安装。)optionalDependencies:可选依赖。意味着该依赖是可选的,打包项目的时候不会管这个依赖,打包发布后别人下载的时候,看到package.json的optionalDependencies有依赖也会先尝试去下载,如果下载失败也不会报错。devDependencies:这个库不是 自己的项目给别人用时所必须的。只是用于开发的库,打包后不需要该库就能正常运行。npm无论在打包的时候会忽略该字段下的依赖,并且在打包发布后,别人npm下载使用的时候,也会忽略这个package.json的devDependencies字段。典型的例子比如语法检查库eslint。
省流版速查表:
bundledDependencies最简单,该依赖已经在项目中了,不需要再安装dependencies最常用,表示该依赖我需要用,请你安装peerDependencies该依赖我需要用,请你安装optionalDependencies该依赖我不一定需要用,但请你先安装devDependencies该依赖我一定不用,是用来开发的,请不要安装
下面是一些安装时的参数,规定了使用的库的定位:
-S, --save - 包将被添加到 dependencies。 -D, --save-dev - 包将被添加到 devDependencies。 -O, --save-optional - 包将被添加到 optionalDependencies。
这些参数对于 uninstall 同样生效,表示从相应的范围内移除依赖。
当使用上述任何选项将依赖保存到 package.json 时,有两个额外的可选标志:
-E, --save-exact - 会在 package.json 文件指定安装模块的确切版本。 -B, --save-bundle - 包也将被添加到 bundleDependencies。
对于这些依赖的管理 npm 的 node_modules 做的有些不尽人意,有很多缺点,比如速度、磁盘占用空间等。pnpm 等包管理工具的出现,缓解了这些问题。
版本声明
npm 允许的版本声明方式十分多样,比如 tag 标签:
version- 安装一个确定的版本,遵循“大版本.次要版本.小版本”的格式规定。如:1.0.0。~version- 以 ~1.0.0 来举例,表示安装 1.0.x 的最新版本(不低于 1.0.0)。但是大版本号和次要版本号不能变。^version- 以 ^1.0.0 来举例,表示安装 1.x.x 的最新版本(不低于 1.0.0),但是大版本号不能变。>、>=、<、<= -可以像数组比较一样,使用比较符来限定版本范围。version1 - version2- 相当于 >=version1 <=version2.range1 || range2- 版本满足 range1 或 range2 两个限定条件中任意一个即可。- tag - 一个指定 tag 对应的版本。
*或""(空字符串):任意版本。- git... - 直接将 Git url 作为依赖包版本
user/repo- 直接将 Git url 作为依赖包版本
也直接将 Git url 作为依赖包版本:
Git Url 形式可以如下:
git://github.com/user/project.git#commit-ish
git+ssh://user@hostname:project.git#commit-ish
git+ssh://user@hostname/project.git#commit-ish
git+http://user@hostname/project/blah.git#commit-ish
git+https://user@hostname/project/blah.git#commit-ish调试脚本
这里的思路是,对于一个个库引入和使用,他们除了作为项目代码本身的依赖来使用,还可以作为开发过程中的工具来使用。
所以 npm 在 package.json 中提供了一个 scripts,配合 npm run xxx 来实现功能,他会去 node_modules 中的 .bin 文件夹中寻找到目标命令文件(这个文件是在该库在安装的时候就顺带下载好的),然后运行它并返回。
如果想要在自己的项目中提供命令给别人使用,package.json 提供 bin 字段。
{
"name": "your-package",
"version": "1.0.0",
"bin": {
"my-command": "./bin/my-command.js"
}
}在这个示例中,在自己的项目打包的时候,bin 会被打包成可执行文件,别人下载自己的库的时候该二进制文件会被丢到 node_modules 下的 .bin 文件夹下。
使用调试脚本缓解误用包管理器
调试脚本有个前置钩子:
"scripts": {
"preinstall": "do something before installing..."
},这个钩子,会在运行 install 命令前被调用。它能够用来防止误用不同(版本)的包管理器。
比如,一个项目的包管理器使用 pnpm,某天你打开项目继续开发,稀里糊涂的输入了一个 npm i xxx 来安装依赖,然后看到一大片爆红后狂按 ctrl+C ....这事我觉得谁都干过。爆红无所谓,关键是 install 这个命令直接的改动了 node_modules 文件夹,最终导致项目跑不起来了,只能狼狈的把 node_modules 删掉重新安装...
preinstall 前置钩子命令避免了这个问题:
"preinstall": "npx only-allow pnpm"only-allow 是一个第三方库,用于判断调用 install 的时候的包管理器是否为期望的管理器. npx 会临时把它后面跟的库下载下来执行并缓存。
对于其他的命令,如 run,他们只要不直接的改动项目内的文件,运行爆红则是可以接受的,仅仅这条前置钩子虽然不全面,但已经比较大程度的避免了毁灭性的打击.
另外,一个好的建议是:
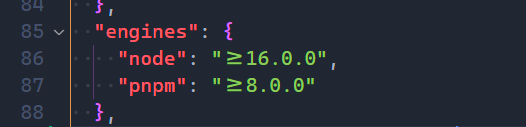
engines 字段是一个好习惯,它最大的作用不是告诉 npm 当前项目的运行的 node 环境是怎样的,而是告诉人这个信息。有很多项目都不喜欢加这个字段,导致别人克隆下来之后因为 node 版本差异不能用。这里的第二行 pnpm 并不是官方定义的字段,而是自己加的,这样做更加语义化。这里使用了 ^,它表示大版本对上就行。由于没有进行过测试具体的兼容性,所以这里就先用了大版本。
最后的包管理器
包管理工具只有 npm 是不够用的,比较常用的还有包管理器 pnpm,yarn ,他们的出现都是因为 npm 的“不思进取”。他们都是工程化的最基础的工具。
在比较新的提案中,corepack 被引入,旨在取代掉 npm。它的 github 自我简介写的十分幽默,讽刺自己是用 npm 安装的:
比较新的库,都已经开始支持他了。它目前还处于实验性阶段,但是已经内置在 node 里了。
具体来说,官方给出的定义是,他是一个“包管理器的管理器”,未来的 node 版本中,npm 将被计划移除,而植入它。这样做的想法是,包管理器实际上是可以放到云端上的,也就是说,当我们需要用包管理器安装依赖的时候,利用 corepack 远程的将包管理器下载下来,并缓存。这样做的好处就是,我们不再需要内置本地包管理器了。这意味着,我们的电脑只要有 node,就免安装的随便敲 pnpm、yarn、npm,而且版本还是根据当前项目自动识别的。
corepack 的使用
corepack 没有选择破坏性的改动,要求我们使用前,必须要卸载掉之前的 pnpm 等东西,但是它还是建议我们先卸载掉他们:
npm uninstall -g yarn pnpm对于 npm,由于它是比较特殊的直接内置在现存的 node 中的,所以 corepack 将它的处理单独划了出来,即默认不去处理 npm,也就是说,我们在安装了 corepack 后,还需要手动去开启它:
npm install -g corepack
corepack enable npm这样,我们重新开一个黑窗口,随便输入 pnpm ,就会发现,大概率都不能用了。完事(x
实际上,之所以不能用,是因为 corepack 的机制导致的。当我们运行这些命令的时候,命令被拦截,corepack 是这样做的:
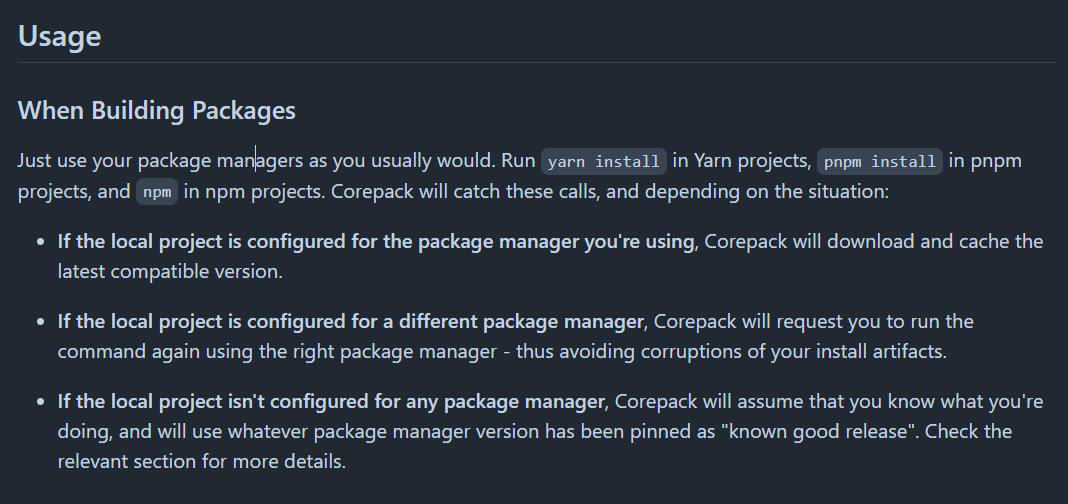
corepack 会去找当前文件夹下有没有 package.json,并且该文件中是否存在字段:
{
"packageManager": "yarn@3.2.3+sha224.953c8233f7a92884eee2de69a1b92d1f2ec1655e66d08071ba9a02fa"
}这个格式是严格正则匹配的,也就是说,值必须是包管理器名@x.y.z。x,y,z 都不可省略。后面的是哈希签名,一般可以省略。
如果找到,就提示是否下载;如果找不到,就去使用当前全局的默认包管理器。
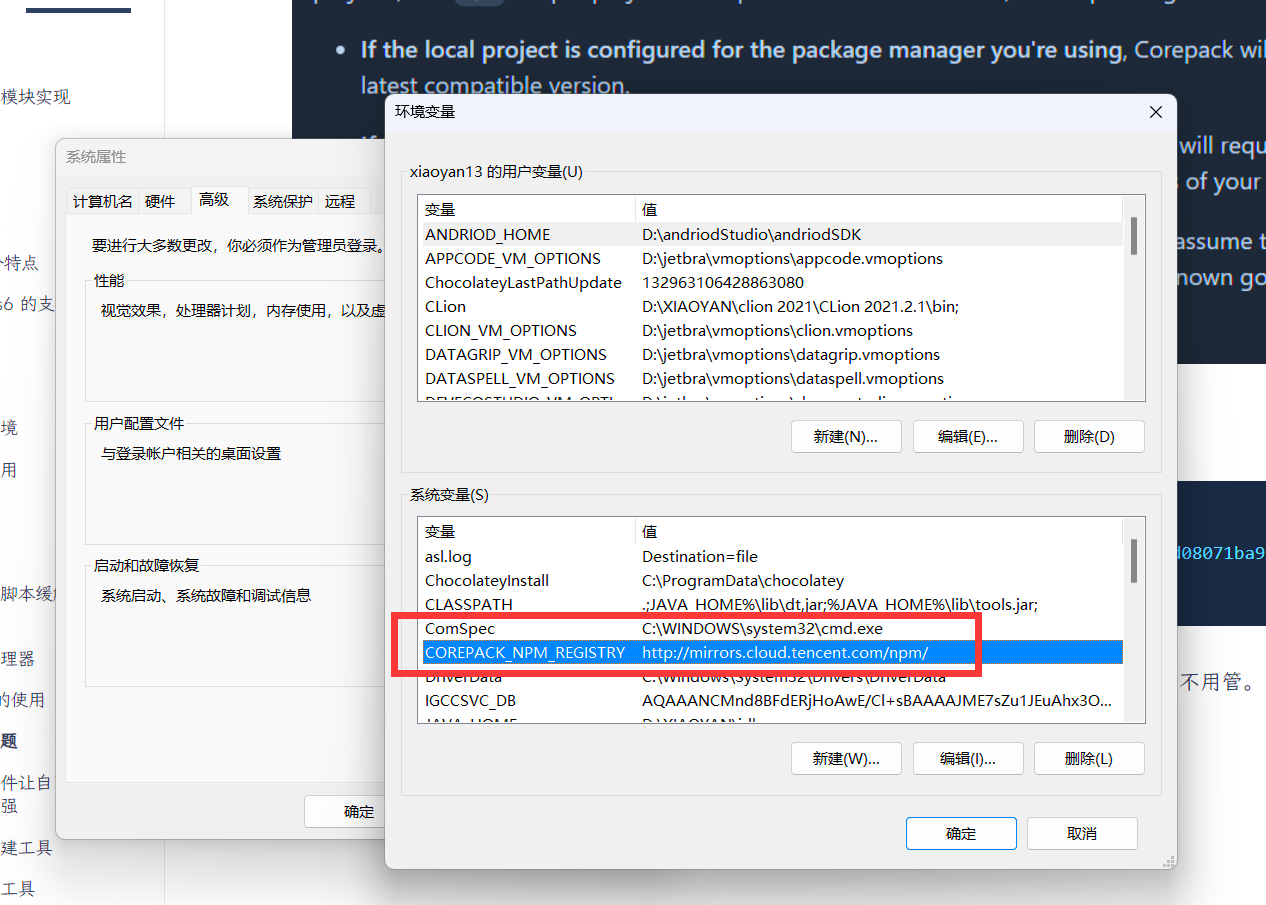
由于 corepack 仍然存在一些网络 bug,所以建议在系统环境中配置下它的 npm 镜像源:
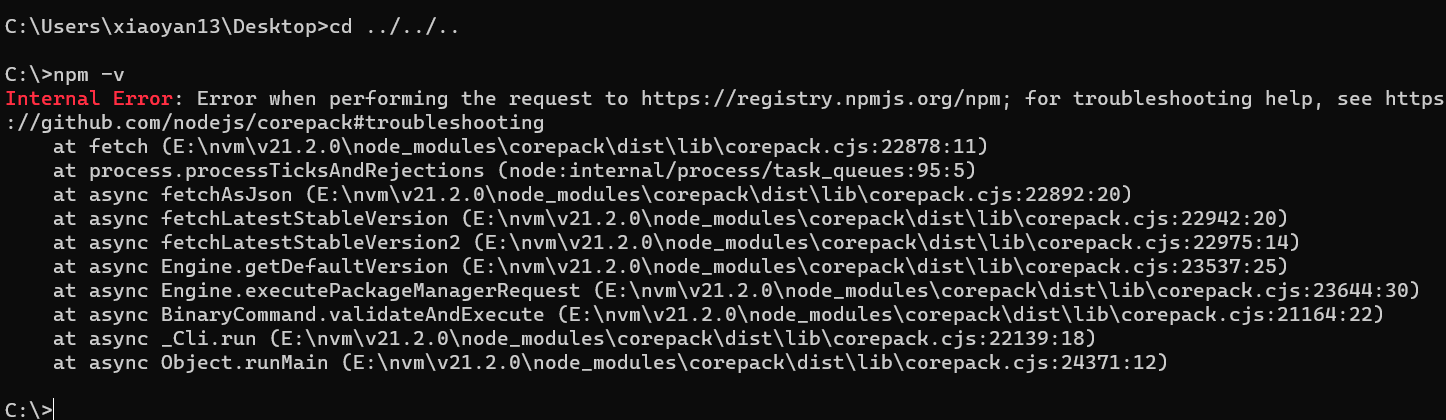
防止在使用的时候报错:
常见指令如下:
corepack install # 下载当前项目中制定的包管理器并缓存。如果找不到 package.json,该指令静默无效。
corepack install -g xxx # 下载并安装指定的包管理器,让他们在系统全局范围内生效。也就是全局应用某个包管理器
corepack use xxx # 重写当前项目下的 package.json 指定的包管理器。如果找不到 package.json,则创建。
corepack up # 更新当前项目下的包管理器到最新版本,如果找不到 package.json。则表示全局更新
corepack enable xxx # 将某种包管理器纳入 corepack 管辖。默认状态下,只有 npm 不归它管。
corepack disable [kind] # 全局禁用某种包管理器。是某种,而不是某个。它的原理是直接找到 node.js 的安装路径,并把相应的包管理器的二进制文件给直接删除掉。相互导入问题
虽然两种模块不允许直接相互交互,但是考虑到向后兼容性,还是存在少量的相互导入的方法:
- CJS 加载 ES6 模块:
(async () => {
await import('./my-app.mjs');
})();import() 方法在 CJS 系统中被实现,用于整体导入一个 ES6 模块。这个导入过程的接口获取和 ES6 是相同的,都是直接取得引用,并没有说底层把 ES6 转换为了 CJS 模块。
- ES6 加载 CJS 模块
// 正确
import packageMain from 'commonjs-package';
// 报错
import { method } from 'commonjs-package';需要注意的是:
ES6 模块的 import 命令 只能整体加载 CJS 模块,不能只加载单一的输出项。这意味着我们在导入后, 往往还需要 . 一下才能用,这和以往直接使用的差异有时候会产生强迫症:
import packageMain from 'commonjs-package';
packageMain.xxx(); // 如果你需要用该模块提供的某个东西...这里是一个函数。这就不如 import { xxx } from '...' 结构来的好看了,但是却不能这样写。这里使用的 import 命令导入的是 CJS 模块,即取得的具有拷贝特性而不是引用。
提供中转文件让自己的模块导出兼容性更强
通过上面两种手段,就可以做到导入已有的 js 代码时,既可以 ES6 导入,又支持 CJS 导入。
那么如何让自己的模块,被别人使用的时候能够同时兼容 CJS 和 ES6 呢?
不通过构建工具
如果自己的模块是 CJS 格式,别人是 ES6,那么只需要在项目的根目录,提供一个中转文件myModule.mjs:
// mjs
import cjsModule from '../index.js'; // 默认导入
export const foo = cjsModule.foo; // 这意味者别人使用时可以找到该 .mjs 文件可以把这个文件的后缀名改为 .mjs 直接丢到根目录,一个典型的例子就是 knex。
如果自己是 ES6,别人使用的是 CJS,那么其实不需要管,因为他可以、也只能用 import() 加载你的代码。
当然,也可以提供一个 .cjs 后缀的中转文件:
// cjs
(async () => {
const myModule = await import('myModule');
module.exports = myModule;
})();借助构建工具
在实际的 js 库的开发中,大部分人会选择借用构建工具来打包代码来发布。上面举的一个 knex,是无意中发现的,没有使用构建工具,而是自己手写了一段构建代码。类似的情况还出现在 vue-core 中。所以,对于高性能要求的小型库(这个核心只有 1-2 MB),选用构建工具不是明智之举。
现在,主流的构建工具有三类:vite,webpack,rollup。
vite适用于 js 网页开发,他强不在构建打包,而是热更新,也就是前端,根据es6 + http query params来实现快速的热更新。rollup更适用于 js 库的开发,也就是工具链,他能够打包出更加精简的代码。
所以,webpack 的处境很微妙,在前端上,热更新的开发体验比不过 vite,在后端上,打包的体积比不过 rollup。算是什么都能干,但什么都不精。
从网上来看,大多数人认为 rollup 在库开发中碾压 webpack。
在后端的热更新上,对应的工具为 nodemon。
https://segmentfault.com/a/1190000038708512
rollup 打包生成入口文件:
https://cn.rollupjs.org/configuration-options/#output-file
提供入口
除了提供入口文件,还必须要在 package.json 文件,重写 exports 字段,指明两种格式模块各自的加载入口。这些字段在后面.
Node.js 工程的模块配置
我们把相关字段的语义,划为两种应用场景:开发时和运行时。
package.json 提供了一些有用的字段,用于让一个项目既可以被用作 cjs 也可以被用作 mjs。
{
"type": "module"
}一个项目默认是通过 cjs 模块构建,通过该字段来声明,自己的项目在开发时是 es6 模块。
{
"main": "./dist/index.js",
"module": "./dist/index.mjs",
"types": "./dist/index.d.ts",
}- main: 指定 使用时 commonjs 引入方式的程序入口文件
- types:指定 使用时 本包环境的
.d.ts类型声明
这里的 modules 字段是一个很容易造成误解的字段,它并没有任何意义,也就是说,它会被 npm 自动忽略,无论是开发还是被当做库运行的时候。
官网阐述了该字段的历史作用:

也就是说,这个"module"字段是给构建工具看的,库的打包构建,也就是开发时,构建工具可以识别该字段作为 ESM 模块的入口文件。
npm 提供了 exports 作为 使用时 的入口文件标识,它存在的时候,优先级比 main 高。
{
"exports": {
"node": {
"./features/": "./src/features/",
".": {
"types": "./dist/index.d.ts",
"import": "./dist/index.mjs",
"require": "./dist/index.js",
"default": "./main.js"
},
"./features/private-internal/*": null
},
"default": './feature.mjs'
},
}它提供了Subpath patterns和Conditional exports,来为不同的导入场景,提供不同的导出。
node,default(node和浏览器)的环境区分types,import,require,default:模块,类型区分映射:
*和**通配符私有文件:
null的支持
如果提供 exports 字段,还将支持自我引用(Self-referencing),也就是说,一个项目可以在开发过程中导入自己:
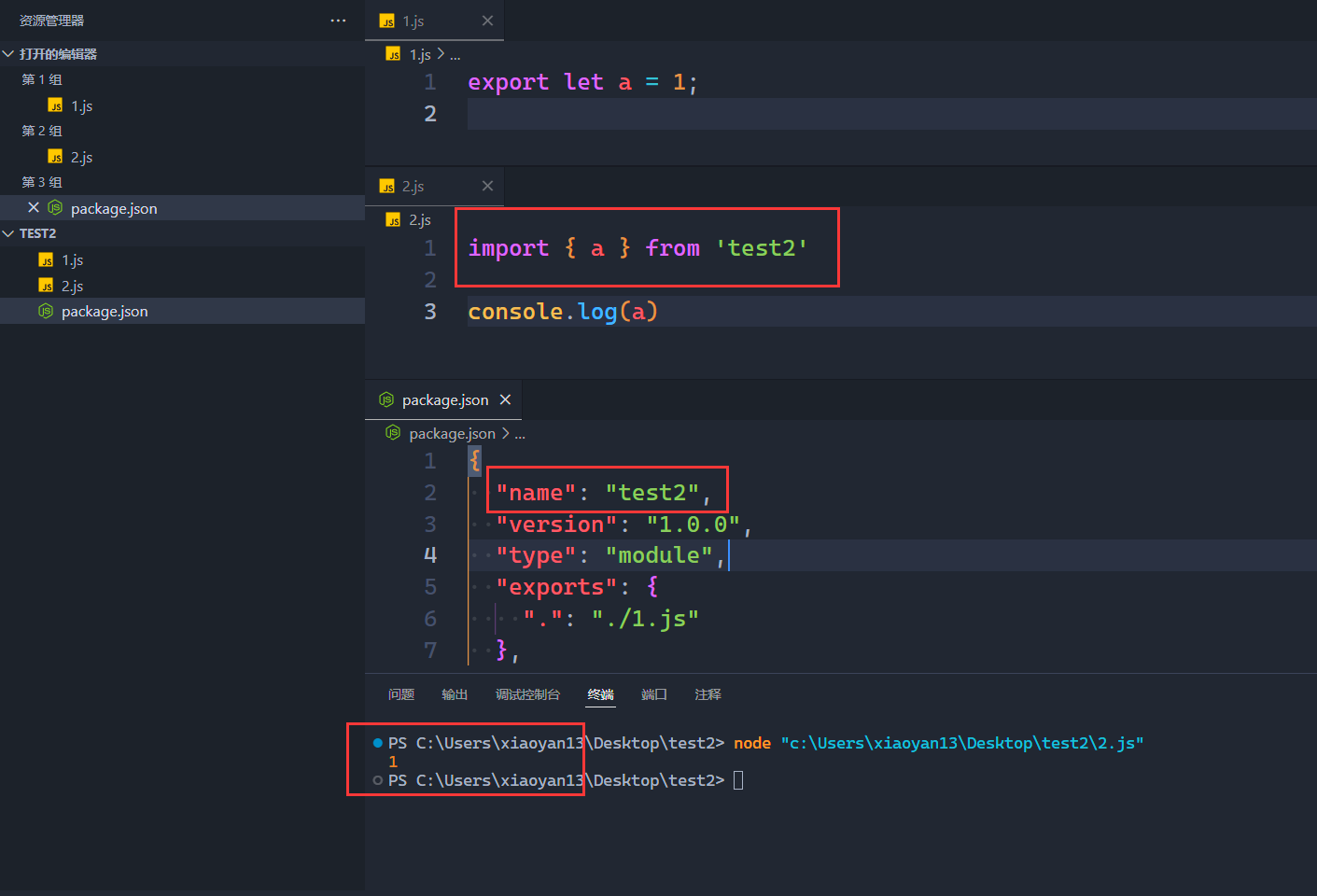
这个东西我觉得是有一些用的,就比如我们的项目存在一些全局的 js 变量,他们是属于我们这个项目自己产生的,那么我们就可以把他们导出出去,项目的其他位置就使用就可以之间导入了,而不用使用一堆 ../../.. 来引(当然,对于 ts, 可以配置路径映射 alias。这就暴露出了另外一个问题了,js 和 ts 不是一个语言,或者说,对于模块的处理也各自有一套配置文件。也就是说,掌握了 package.json,又要去配一遍 tsconfig.json。。)
比较相似的还有一个 imports 字段,它也与包与依赖相关,是开发时被使用的字段:
{
"imports": {
"lodash": "./node_modules/lodash-es/lodash.js"
}
}它显式的指定在开发的时候,引用依赖的具体入口文件。它甚至也可以像 exports 那样,指定 node 环境和浏览器环境引用什么文件(看起来有点奇怪,绝大部分开发环境都是 node.js 才对吧...浏览器环境下怎么开发)。
其他字段参见:
TS 下的模块实现
详见同目录下的另一篇文章。